
In a previous post we explored a high performance implementation of a Python Object Detector based on the SSD Inception V2 COCO model running on an NVIDIA Jetson TX2. In this post we will explore how we can implement the same Object Detector using NVIDIA's DeepStream SDK.
Previously, in the process of increasing the observed detector Frames Per Second (FPS) we saw how we can optimize the model with TensorRT and at the same time replace the simple synchronous while-loop implementation to an asynchronous multi-threaded one.
We noticed the increased FPS and the introduced trade-offs: the increased inference latency and the increased CPU and GPU utilization. Reading the web camera input frame-by-frame and pushing the data to the GPU for inference can be very challenging.
DeepStream Object Detector on a Jetson TX2
The data generated by a web camera are streaming data. By definition, data streams are continuous sources of data, in other words, sources that you cannot pause in any way. One of the strategies in processing data streams is to record the data and run an offline processing pipeline. This is called batch processing.
In our case we are interested in minimizing the latency of inference. A more appropriate strategy then would be a real time stream processing pipeline. The DeepStream SDK offers different hardware accelerated plugins to compose different real time stream processing pipelines.
NVIDIA also offers pre-built containers for running a containerized DeepStream application. Unfortunately, at the time of this blog post, the containers had some missing dependencies. For this reason, this application is run directly on the TX2 device.
DeepStream Object Detector application setup
To run a custom DeepSteam object detector pipeline with the SSD Inception V2 COCO model on a TX2, run the following commands.
I'm using JetPack 4.2.1
Step 1: Get the model.
This command will download and extract in /temp the same model we used in the Python implementation.
wget -qO- http://download.tensorflow.org/models/object_detection/ssd_inception_v2_coco_2017_11_17.tar.gz | tar xvz -C /tmpStep 2: Optimize the model with TensorRT
This command will convert this downloaded frozen graph to a UFF MetaGraph model.
python3 /usr/lib/python3.6/dist-packages/uff/bin/convert_to_uff.py \
/tmp/ssd_inception_v2_coco_2017_11_17/frozen_inference_graph.pb -O NMS \
-p /usr/src/tensorrt/samples/sampleUffSSD/config.py \
-o /tmp/sample_ssd_relu6.uffThe generated UFF file is here: /tmp/sample_ssd_relu6.uff.
Step 3: Compile the custom object detector application
This will build the nvdsinfer_custom_impl sample that comes with the SDK.
cd /opt/nvidia/deepstream/deepstream-4.0/sources/objectDetector_SSD
CUDA_VER=10.0 make -C nvdsinfer_custom_implWe need to copy the UFF MetaGraph along with the label names file inside this folder.
cp /usr/src/tensorrt/data/ssd/ssd_coco_labels.txt .
cp /tmp/sample_ssd_relu6.uff .Step 4: Edit the application configuration file to use your camera
Located in the same directory, the file deepstream_app_config_ssd.txt contains information about the DeepStream pipeline components, including the input source. The original example has been configured to use a static file as source.
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=3
num-sources=1
uri=file://../../samples/streams/sample_1080p_h264.mp4
gpu-id=0
cudadec-memtype=0If you want to use a USB camera, make a copy of this file and change the above section to:
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=1280
camera-height=720
camera-fps-n=30
camera-fps-d=1
camera-v4l2-dev-node=1Save this as deepstream_app_config_ssd_USB.txt.
TX2 comes with an on board CSI camera. If you want to use the embedded CSI camera change the source to:
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP 5=CSI
type=5
camera-width=1280
camera-height=720
camera-fps-n=30
camera-fps-d=1Save this file as deepstream_app_config_ssd_CSI.txt.
Both cameras are configured to run at 30 FPS with 1280x720 resolution.
Execute the application
To execute the Object Detection application using the USB camera, run:
deepstream-app -c deepstream_app_config_ssd_USB.txt

The application will print the FPS in the terminal, it's ~16 FPS. This result is very similar to the TensorRT Python implementation where we had achieved 15 FPS in a simple Python while loop.
So what's the fuzz about DeepStream?
In a closer look, we can tell there is a substantial difference. The tegrastats output shows an semi-utilized GPU (~50%) and an under utilized CPU (~25%).

The USB camera throughput is the obvious bottleneck in this pipeline. The Jetson TX2 development kit comes with an on board 5 MP Fixed Focus MIPI CSI Camera out of the box.
The Camera Serial Interface (CSI) is a specification of the Mobile Industry Processor Interface (MIPI) Alliance. It defines an interface between a camera and a host processor. This means that the CSI camera can move the data in the GPU faster than the USB port.
Let's try the CSI camera.
deepstream-app -c deepstream_app_config_ssd_CSI.txt
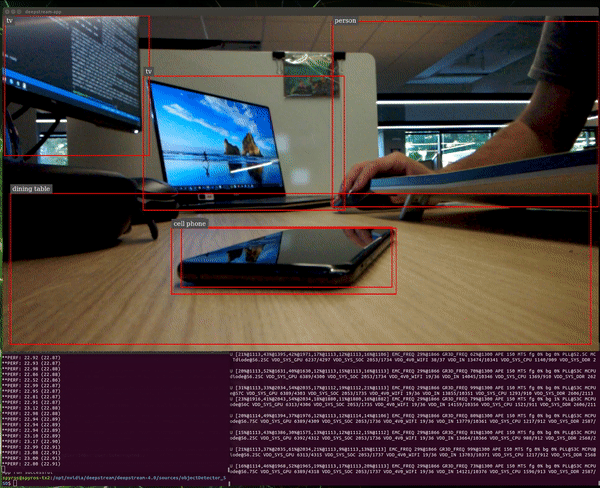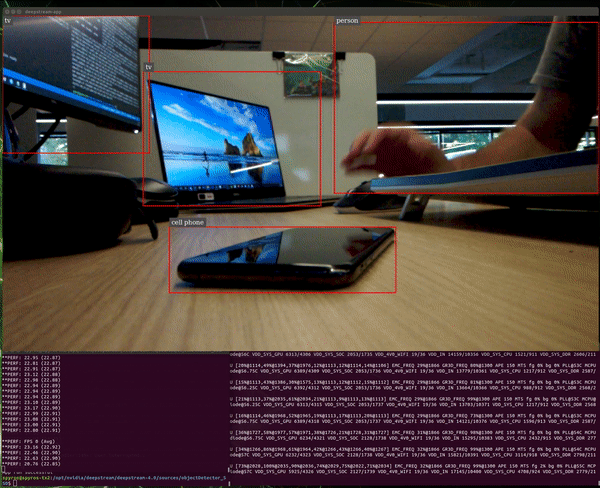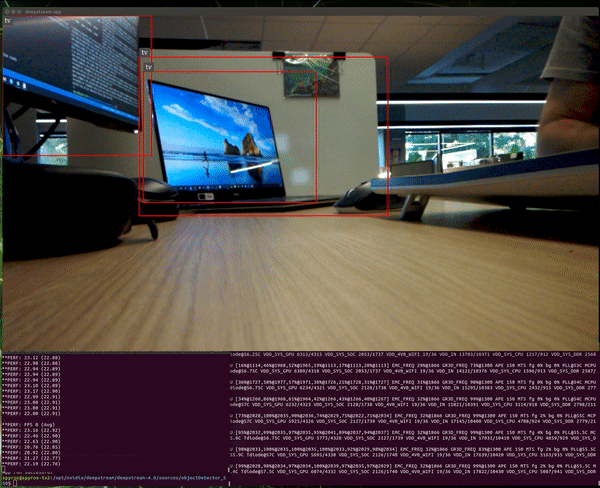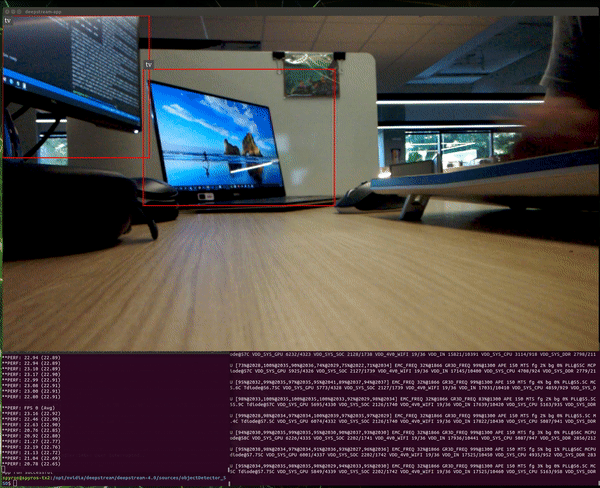
The average performance now is ~24 FPS. Note that the theoretical maximum we can get is 30 FPS, since this is the camera frame rate.
We can see an obvious increase of the system utilization:
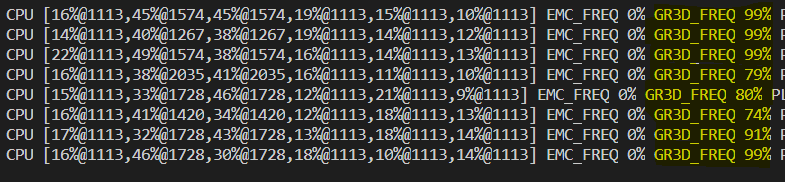
Let's try running both applications side by side:

The GPU now is operating at full capacity.
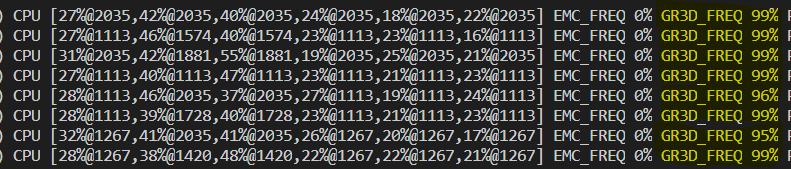
The observed frame rates are ~12 FPS for each application. Apparently, the maximum capacity of this GPU is ~24 inferences per second for this setup.
Note: NVIDIA advertises that a DeepStream ResNet-based object
detector application can handle concurrently 14 independent 1080p 30fps video streams on a TX2. Here we see that this is far from true when using an industry standard detection model like SSD Inception V2 COCO.
What have we achieved: We've explored an optimized streaming Object Detection application pipeline using the DeepStream SDK and we've achieved the maximum detection throughput possible, as defined by the device's hardware limits.